Building Solid Apps which use Public Data
One of the early Solid Apps which both looked nice and was definitely useful was Noel de Martin's Media Kraken. Media Kraken allows you to track the movies you have watched or would like to watch. It does this by making a simple database in the user's pod, and tying that data to the Internet Movie Data Base, IMDB. To add another movie to your collection, you start typing, and it pulls in from IMDB candidate movies which match what you are typing, as you select the the name of a movie. When have selected one, then it is represented by IMDB's miniature picture of the DVD cover. It is neat for the base functionality it gives, but also one imagines in the future, that as we all share our media collections, then we can easily see when you and I have watched the same thing as it will be captured by the same IMDB uri. The set of public URIs in the IMDB public data allows Solid users to coorinate. Yes, solid is desupposed to be decentralized, heer the value of a centralized common data set is clear, and this one is public good to which lots of people have contributed.
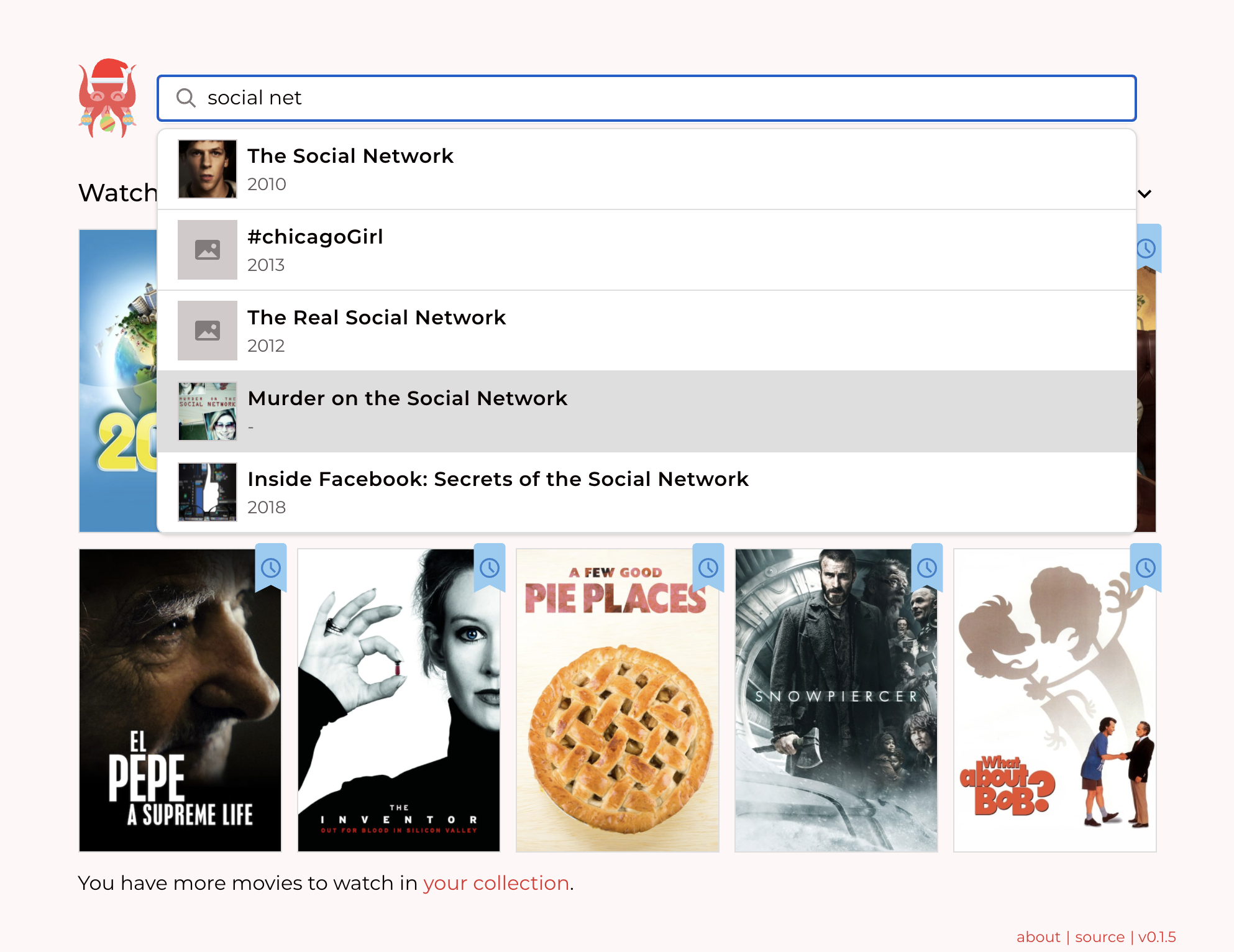
Stepping back, this is a great example of how a user's world is made up of data from across what the ODI calls the Data Spectrum. Some of it is public, like the properties of movies, some of it is shared, like playlists and photos, and some of it is private, like passwords.
Meanwhile, I've been thinking about the public part of of a Solid user's
profile, and felt it would be great to put in some details of what one has been
up to in one's life as well as the bare contact details it has (as of 2020-12 anyway).
Adding this resumée information involves mainly capturing the various
projects, companies and organizations one has been involved in, as student,
volunteer, employee, and on. And just as with the movies I am tracking,
it is useful to tie these organizations into public data. For several reasons
in fact:
- To provide a list of names to pick from, saving the user time;
- To provide interesting data like pictures and location about the thing selected;
- To discover which friends has been involved with the same organizations;
- In the long term, data analysis of things like trends in, say, gender
rights, becomes much more powerful when you have a public web of solid profiles
Data sources and ontologies: Organization
There was a couple of public databases which came to mind, DBpedia and Wikidata. They each have SPARQL endpoints which seemed to work. Wikidata has a really nice playground where you can tweak your SPARQL query and test it instantly. Meanwhile as Solid policy is to use schema.org terms whenever possible, I looked to the class structure of these organizations. I'm using the term 'organization' as a generic one to include companies, universities, projects and so on, partly because that matches both with schema.org's
Organization, and also
Wikidata's Organization which
it gives a number to rather than a name.
Unfortunately, Wikidata, the main source of public data, and schema.org, the main
source of terms systems will be interoperable with, don't completely
agree on the structure of subclasses of organization. Schema.org
says more specific
classes include "Airline, Consortium, Corporation, EducationalOrganization, FundingScheme, GovernmentOrganization, LibrarySystem, LocalBusiness, MedicalOrganization, NGO, NewsMediaOrganization, PerformingGroup, Project, SportsOrganization, and WorkersUnion" including lots of things but not Non-Profit. I made a sketch of a little part of the wikidata classes.
From the UX point of view it is nice to give the user a choice of mutually distinct classes even when life maybe more complex. So the colored ones seems to be fairly easy to understand and so seemed to partition the space fairly cleanly.
I made an executive decision that for now we would assume for now:
solid:InterestingOrganization owl:disjointUnionOf( schema:Corporation schema:EducationalOrganization schema:GovernmentOrganization schema:MedicalOrganization schema:MusicGroup schema:NGO schema:PerformingGroup schema:SportsOrganization ) .
In other words be prepared to mint a solid-specific concept of Organization which would involve just those 7 subclasses.
That allows us to make a form field like
:OrgClassifier a ui:Classifier; ui:label "What sort of organization?"@en; ui:category solid:InterestingOrganization .
which looks something like this:


Data sources and ontologies: Occupation
What about the connections between people and organizations? Schema's Role class looks interesting, though apparently to be used in a strange way, with incoming and outgoing arcs both "athlete" which is weak. What existing work is there out there? A quick search reveals Uldis Bojar's 2007 >ResumeeRDF and of course the LinkedIn API. The latter mentions some enumeration types, like:
- experience – A list of experience levels, one or many of “1”, “2”, “3”, “4”, “5” and “6” (internship, entry level, associate, mid-senior level, director and executive, respectively)
- job_type – A list of job types , one or many of “F”, “C”, “P”, “T”, “I”, “V”, “O” (full-time, contract, part-time, temporary, internship, volunteer and “other”, respectively)
Clearly, as LI is very much the dominant player in the CV space, being able to interoperate with them would be valuable. We imagine that they have their own carefully curated databases of schools, companies, job types, which is not public and they may regard as the crown jewels not to be shared. In an ideal future world one would be able to sync both ways between one solid CV and Linked In - and their competitors. So a deeper investigation of the LinkedIn API would be a good ideaat some point.
A CV entry is basically a relationship between people and organizations. The address book vcard gives people, augmented/grounded using their WebIds, and organizations, augmented/grounded by their public IDs. The start and end date there are a few contenders (iCal events, ResumeeRDF) but as schema has that, let's use that. The Solid world is like a bag of chips -- many different languages. Typical documents/databases have terms from many different ontologies. You ignore what you don't understand, or you don't need to use. If a vocabulary you like or are using already you are using has a term, then use it. Don't try to get everything into the same ontology.
Now the remaining thing we need to model
is the relationship between the two: the job, the exact role. The ultimate
find here would by an up-to-date list of occupations translated into many languages.
Then I could fill in my CV in English and you could set your browser to Arabic
and read my CV in Arabic.
Wikipedia quotes the UK Office for National Statistics
as listing 27,966 job titles. (Check it out - no Quarterback but Quartermaster and Putter-on (glue) and putter-together (scissors)). Clearly a great resource but UK-culture-specific. Does the ILO have something more general? Yup - about labour surveys, pointers to ICLS whose 1992 report mentions "Some 30 countries have already either established, or are
in the process of creating, a national standard classification of occupations
similar to ISC0-88."
The latter has a spreadsheet
with 500 posts in 10 categories in English, French and German.
There is ESCO,
which is the EU equivalent, ISCO-compatible, more recent and notes "ESCO does not adapt the ISCO occupation groups, but the Commission manages translations of ISCO labels in the official languages of the European Union." Not to mention "The full ESCO dataset can be downloaded in turtle format from the
ESCO Service Portall", "and each module is available in 26 European languages and in Arabic". (my emphasis). Restful API ...at https://ec.europa.eu/esco/api/ ... including search by name substring. Examples:
- Art Director in JSON.
- The URI of the object actually gives 500 error - so not strictly linked data
- /esco/api/search?language=en&type=occupation&text=softw - occupations including "softw"
A SPARQL endpoint would be nicer.. There is the EU Open Data Portal SPARQL service. Does it have ESCO?
Is this ESCO stuff available in fact in wikidata? There are 251 mentions of ESCO IDs in wikidata. Not typically in 27 languages. Can we use wikidata Profession? 126 subclasses, pretty mixed, and 105k transitive closure subclasses including things like Mayor of Halifax! So nothing like as clean, international, or complete. The ESCO occupations seem to be the ones to pick.
Looking through the open HR and finding the JDX work on job opening exchange, that mentions, when talking about job classification "Industry code identifying the primary activity at the location of employment (e.g., NAICS in the U.S. and ESCO in the EU)" but NAICS seems to have codes for industry types, not job types.
Now we have to figure out the shape for the resumes entry itself, and its discovery. A discussion in Gitter suggested that a CV should be a different resource from one's profile. Down the road, we may have a different CV shared within each community, but for now let's focus on a primary public one which everyone will be able to see with your profile.

The Linked In APIs for
position,
organization etc use linked-in defined URNs for things like language codes.
Adding to the SolidOS UX
Where to add this to SolidOS? The plan is to extend the contacts management in the Address Book to be much smarter about Organizations. Already we are in a good place in a way, in that we use the vCARD ontology fo storing stuff about Individual, Organizations, and groups of them. So a new contact is either an Individual or an Organization already, and it looks as though we can treat vcard:Organization class as being just the same as the schema one and the wikidata one.
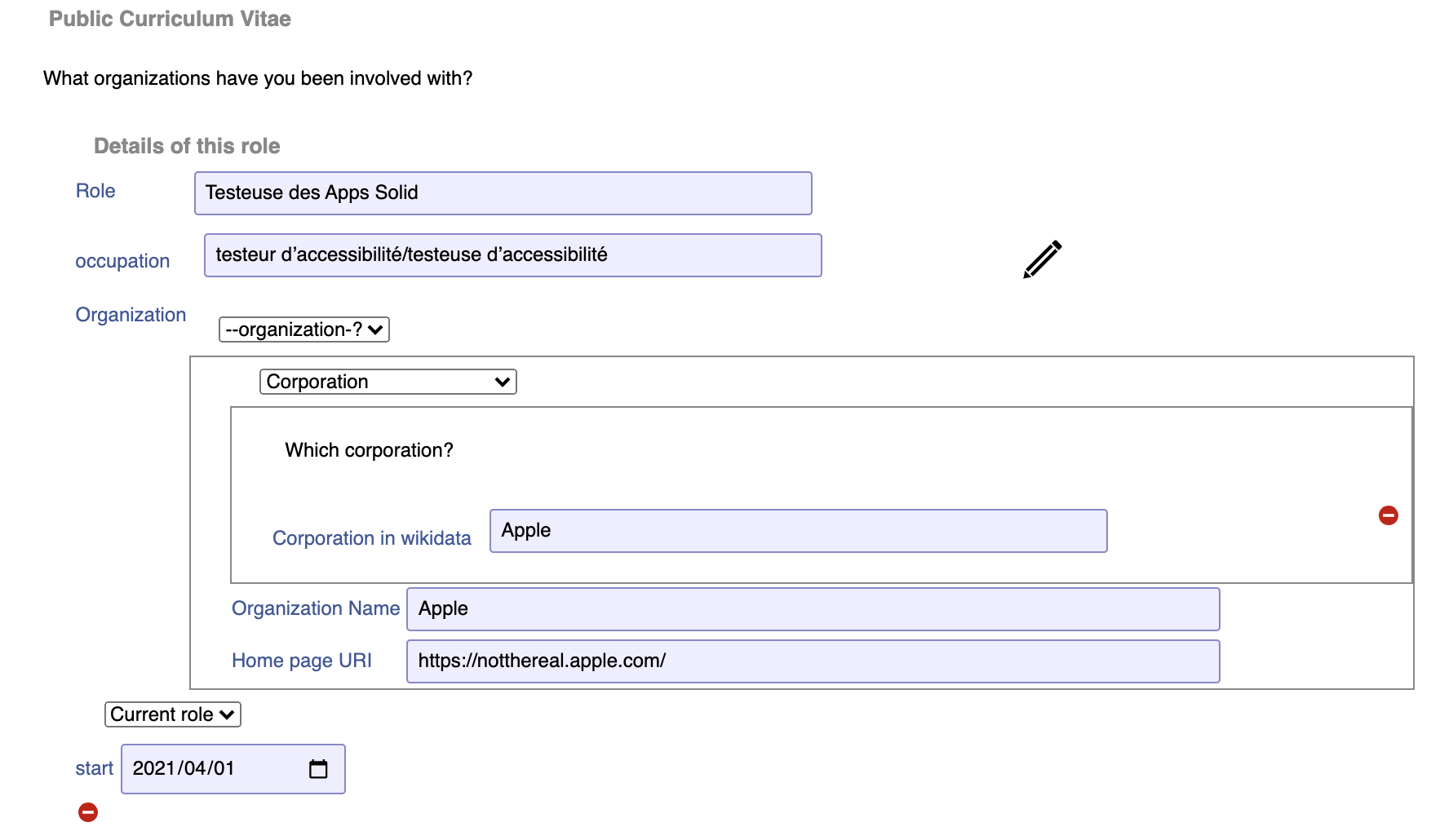
The plan is to make a user workflow in which when you add an organization to your contacts, adding UX to tie the Organization in your contacts to the public data where we can. Should we include project which are public Github, Gitlab, etc projects? Yes but later. Then add a resume form on the profile editor and a resumee rendering on the profile. How about an "Add this to my CV" button any time we are looking at an organization? Maybe.
Changing the Contacts data for an Organization.
This is now (2021-04-02) done. You can press on the search icon, and type in the name of the organization to auto-complete using Wikidata. When you find a public data instance of the organization in question, then some of that data is displayed under the new ID you have found. So the contacts display makes it very clear the provenance of data: what you have stored in your contacts and what is wikidata. You can (on a good day - subject to browser CORS etc) drag an image from the public data into your vcard to keep a link to it.
This is reasonable at this stage when we are editing, though, it may be more useful to merge all the information in to one view.
@@ screen shot
Deciding on the shape
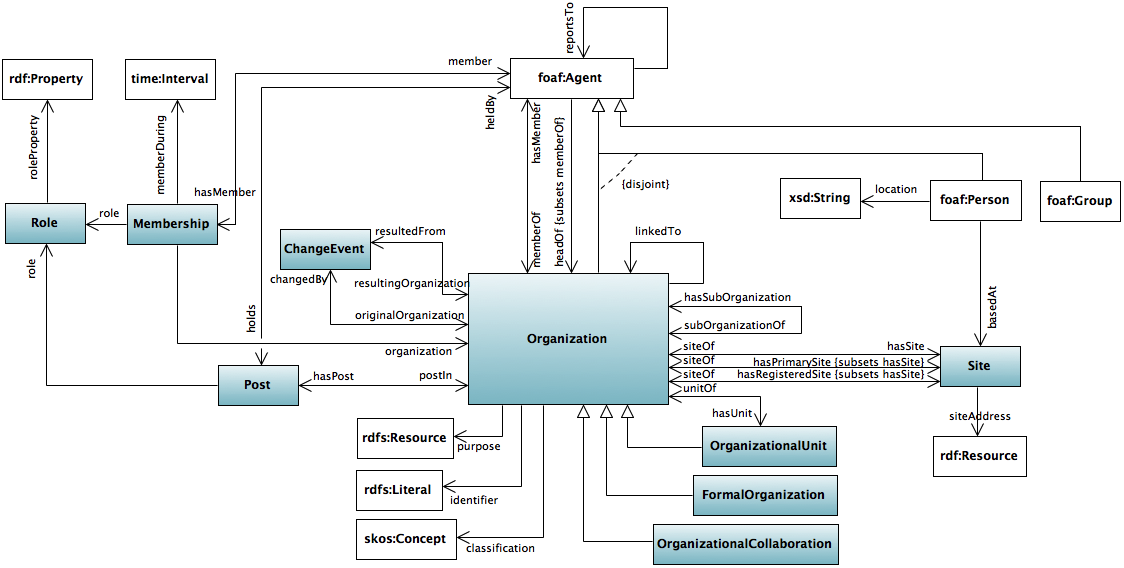
There actually is a whole W3C standard ontology about Organizations. This includes relationships of different organizations, and different people with organizations. It also spends some time thinking about and helping with modeling problems, like moving between the simple triple that a person is an employee of a company to the fact that they had a given role during a given time. the org:Membership N-ary form does the latter, and is what we use. (See the diagram above). So an element in the CV data will look like
<#episode1> org:member <#me>; org:organization <#MIT>;org:role: esco:SoftwareEngineer;schema:startDate 2000-01-01^^xsd:date;schema:endDate 2010-12-31^^xsd:date .
Ordered or unordered?
In fact in a CV there are a bunch of these. Should they be just all linked by org:member arcs to the person, leaving them as an unordered set, or should we allow the user to make the CV in their profile as an ordered list? The writer may prefer to present the various phases in their life to the reader in a specific order -- or should in fact the reader have the option of sorting them in any way? This was a hard one, and may be reversed later. If the list is ordered then it looks like:
( <#episode1> <#episode2> ) org:member <#me>.
which stretches the semantics of org:member which is defined
to have a org:Membership as its subject, not a Collection/List/Array thing.
<#me> org:isMemberOf ( <#episode1> <#episode2> ) .
If we don't have the ordered list, then when we display these, we can decide to order them --- first current positions by most recent start date at the top, and then former positions by most recent start date (or end date?). Theer may be smarts in the display collapsing life episodes with different roles at the same company together of course. "MIT: undergrad 200-2004, grad student 2004-2008". Extra points for "MIT: undergrad 200-2004, grad student 2007-present".
Ok, lets go with unordered. Of course writers can also select the style of profile display they want, just as they can chose the colors of it. And readers in their preferences can say how they would like all CVs they read to be displayed. And the readers in the end must win. The writer are fundamentally publishing data, not documents, and for accessibility alone, but also the power of of re-use, readers have the last word.
The form
:involvementWithOrganizationsForm a ui:Multiple;
ui:label "Involvement with Organization";
ui:property org:member; ui:reverse true; # link back from role to member
ui:ordered false; # Allow user to order CV secions rather than force date order? No.
ui:part :membershipForm.
:membershipForm a ui:Group; ui:parts ( :orgField :roleNameField :orgField :startField :endField ).
:startField a ui:DateField; ui:property schema:startDate; ui:label "Starting"@en, "Début"@fr.
:endField a ui:DateField; ui:property schema:endDate; ui:label "Ending"@en, "Fin"@fr.
:orgField a ui:Choice; ui:label "Organization"@en, "Organization"@fr; ui:canMintNew true;
ui:from vcard:Organization; ui:property org:organization.
:roleNameField a ui:SingleLineTextField; ui:property vcard:role; ui:size 60 .
>Let's add to the form an AutoComplete form which uses the ESCO list of occupations:
:escoOccupationField a ui:AutocompleteField;
ui:label "occupation"; ui:size 60;
ui:property org:Role;
ui:dataSource :ESCO_Occupation_DataSource;
ui:targetClass schema:Occupation .
:ESCO_Occupation_DataSource a ui:DataSource;
schema:name "ESCO";
ui:targetClass schema:Occupation ;
schema:logo "https://ec.europa.eu/esco/portal/static_resource2/images/logo/logo_en.gif";
ui:searchByNameURI "https://ec.europa.eu/esco/api/search?language=$(language)&type=occupation&text=$(name)".
Note the ESCO_Occupation_DataSource Data Source object which tells the autocomplete form where to get the data from. Specifically it has to know (with searchByNameURI) the URI template for searching for occupations by name. So code up the Autocomplete form field, the widget it uses, and the public data access, and here you go:

As you type in the occupation, the autocomplete suggestions are displayed in a list

which get shorter as you type more

until there is only one left. Then you press the green check mark to save the data. Bingo.
Using Wikidata
The Wikidata-based form fields were similar, but different in that Wikidata has a SPARQL endpoint, which ESCO does not (yet?). Wikidata is less organized. A 2020 paper about YAGO 4 discusses the different levels of organization and disorganization in the various public Knowledge Bases. YAGO4 looks like a good one, and we may fold that in, but for now we will continue with Wikidata.
The whole design of the autocomplete system is affected by the fact the query takes a certain amount of time, compared with having everything in memory. One parameters is how many characers you let the user type before you even do the first query. This is at the moment set at 4, so that you might expect to cut the total number of things down to those which start with those letters. The search we do is a subtring search do that one can start with the second word rather than having to know exactly what the first word is ("Beatles" or "The Beatles"? "University of Oxford" or "Oxford University"). Should the threshold number of characters be made a paremeter in the AutocompleteField of the form? Here for completeness is a state diagram for the widget, though this note is supposed to be more about the public data than autocomplete.

Wikidata has a lot of Organizations which we can use for that part of the CV entry, but the clases are less organized. One trick is to get the SPARQL query engine itself to find all the subclasses of the target class, and then to find instances of of those classes. A problem though can be the time it takes the query to run, and you might end up with thousands of very small subclasses which contain hardly anything. Wikidata does have labels for things in lots of languages and it also has a non-standard but useful SPARQL extension to request labels to be automatically filtered according one's preferred languages. You have to think of this when you set the LIMIT for the query -- the number you are asking to be sent back. If you are doing the language filtering yourself, then the LIMIT has to be an order of magnitude bigger.
One way to make the system work better with many organizations in the public data was to get the user to select which subclass of organization it is, from the list above of subclassses "solid:InterestingOrganization", so there will be fewer to chose from, smaller results from the SPARQL query. Then for each subclass where you could expect Wikidata to have instances, there is a separate version of the autocomplete field, targetting a different corresponding Wikiidata class.
Here is form field and data source for finding a Corporation by name.
:CorporationAutocomplete a ui:AutocompleteField;
ui:label "Corporation in wikidata";
ui:size 60;
ui:targetClass <http://www.wikidata.org/entity/Q6881511>; # Enterprise
ui:property solid:publicId; ui:dataSource :WikidataInstancesByName.
:WikidataInstancesByName a ui:DataSource ;
schema:name "Wikidata instances by name";
ui:endpoint "https://query.wikidata.org/sparql" ;
ui:searchByNameQuery """SELECT ?subject ?name
WHERE {
?klass wdt:P279* $(targetClass) .
?subject wdt:P31 ?klass .
?subject rdfs:label ?name.
FILTER regex(?name, "$(name)", "i")
} LIMIT $(limit) """ .
Here the API URI template has been
replaced witha SPARQL query template
and a SPARQL endpoint.
Note the targetClass is here given on the form feild
rather than the Data Source, as this allows the data
source to be shared by different Fields with differnt target classes.
Here are the forms which form part of the "Edit my profile" function.
Here is our test individual filling in a current role editing their profile:
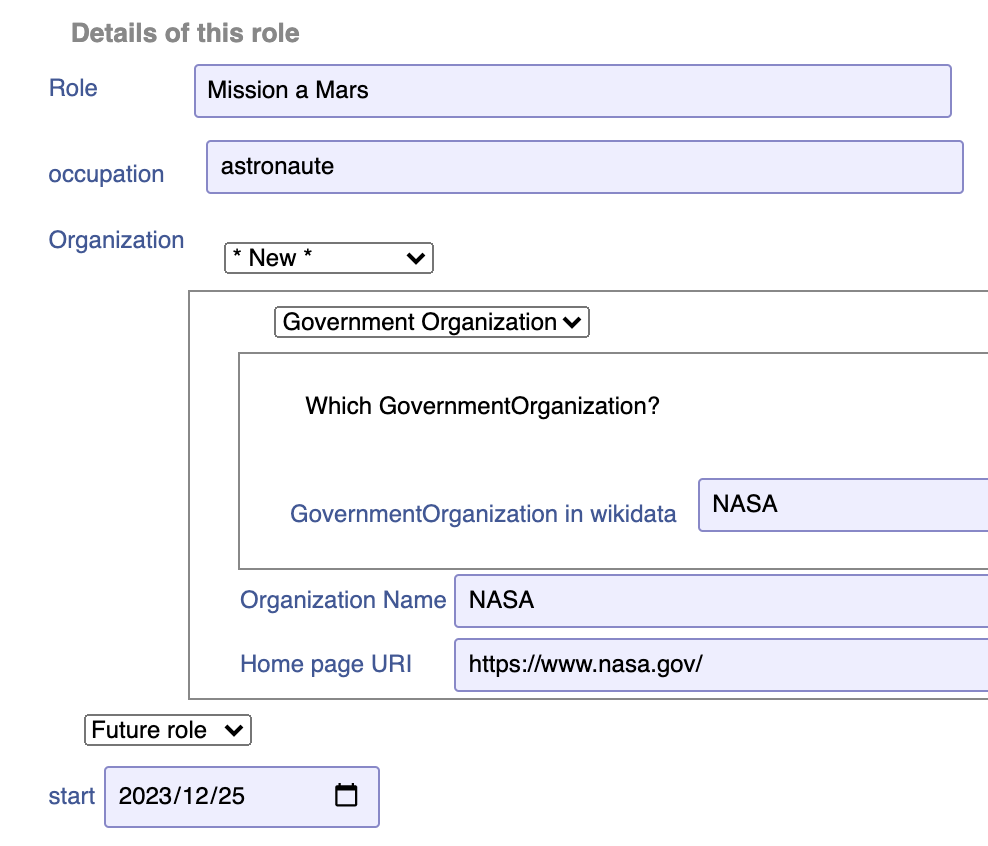
They add a past role or two, and also a hopeful future role:
People who go any check them out can then see thisin the view of profile

That was added to a hand-coded view of the profile data done using React.
So we have a profile editor using a form which captures the data, and establishes identity of organizations, occupations and skills -- and languages -- using public data, and we have a tweak to the profile to add a card for the CV data. That is more or less what we were aiming for, to time to conclude the rambling breadcrumbs we are leaving. There is one part of the use of pulic linked data though which we need to mention, though it wasn;t necessray to do what we just did. That is, we need to provide functionality to actually read daat about these things now the user has selected them! We can't just use HTTP "GET" on those URIs.
Replacing the GET
So we have shown how we have built an Autocomplete form field for allowing a user to select a public object from the public data world and link to it from their Solid pod. Once we have these public data objects, ESCO occupations or Wikidata Organizations, or whatver, we do have to treat them differently from the normal Solid things in our pod. In the Solid linked data world, the convention is that if you look the URI of something, you get can a reasonable quantity of data you are likely to be reasonably interested in. This is not the case for most public data things. Some do not support HTTP GET at all; some do but give you a huge amount of data, or give you stuff but not what you want.
So just as we use API URI templates and SPARQL query templates to search by name, we can use them also to basically look up the URI. Here is an example. Note how CONSTRCT allows you to convert from the internal vocabulary of the server to the common vocaularies we want to use in the Solid ecosystem.
prefix vcard: <http://www.w3.org/2006/vcard/ns#>
CONSTRUCT
{ wd:Q49108 vcard:fn ?itemLabel.
wd:Q49108 rdf:type ?klass. ?klass rdfs:label ?klassLabel; rdfs:comment ?klassDescription .
wd:Q49108 schema:logo ?logo;
schema:image ?image;
schema:logo ?sealImage;
schema:subOrganization ?subsidiary .
?subsidiary rdfs:label ?subsidiaryLabel .
?supersidiary schema:subOrganization wd:Q49108 .
?supersidiary rdfs:label ?supersidiaryLabel .
wd:Q49108 schema:location ?location .
?location schema:elevation ?elevation .
?location wdt:P131 ?region . ?region rdfs:label ?regionLabel .
?location wdt:P625 ?coordinates .
?location schema:country ?country . ?country rdfs:label ?countryLabel .
}
WHERE
{ optional {wd:Q49108 rdfs:label ?itemLabel} .
optional {wd:Q49108 wdt:P154 ?logo .}
optional {wd:Q49108 wdt:P31 ?klass .}
optional {wd:Q49108 wdt:P158 ?sealImage .}
optional {wd:Q49108 wdt:P18 ?image .}
optional { wd:Q49108 wdt:P355 ?subsidiary . }
optional { ?supersidiary wdt:P355 wd:Q49108. }
optional { wd:Q49108 wdt:P276 ?location .
optional { ?location schema:eleveation ?elevation }
optional { ?location wdt:P131 ?region }
optional { ?location wdt:P625 ?coordinates }
optional { ?location wdt:P17 ?country }
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "fr,en,de,it". }
}
With the Autocomplete as a way of introducing public data endpoints into the
web of linked data on people pods, and with SPARQL construct templates as a way
doing the lookup, we can now build apps which bridge the two worlds
of private data and public data. Our lives are interconnected things private, shared
and public, and so our data too must be able to represent this.
In the time it took to explore this -- and write these breacrumbs for others to follow should they wish -- we looked DBPedia, Wikidata, and ESCO. We also found out about another very intersting resource,YAGO 4. This is a public dataset whch takes the Wikidata instances of things, gives them human-readable names insead of numbers, and connects them to the schema.org ontology. So maybe future exploraions will use that as a base. Hopefully we will be able to pull them in just be writing a new DataSource.
__________________________________________________________________
Notes
- The org ontology spec diagram shows inverse predicates hasMember and member . This is confusing, but turns out to be a bug fixed in the errata. So we use member.
{kind=link}
Things we thought about but have not done:
- A nice pane for public data about an organization, using logos and pictures - and stucture
- "Add to my CV" button on vcard when any logged in user is looking at an Organization they have in their own address book. Probably more frsutrating that useful, as you use it so rarely.
- Possibly, look at adding way to configure rdflib.js to automatically do the right SPARQL instead of looking up public data URIs, which doesn't really work.
- Authors
-
 Solid Open Source Operating System , Tim BL
Solid Open Source Operating System , Tim BL
- Modified
- Language
- English
- License
- CC BY-NC 4.0
- Document Status
- Draft